

 UA
UA EN
EN


Web scraping au service des marques

Le terme « scraping » désigne l’action d’extraire des données massives (métadonnées) provenant de sites web. A titre d'exemple, chacun d'entre nous est un scraper, certes à l'échelle microscopique, dès lors qu'il fait l'action de « copier-coller » une information glanée sur un site web. Le but du web scraping est de collecter automatiquement et massivement l’information disponible dans le web afin de répondre aux questions business.
L'objet de cet article est d'expliquer pourquoi certaines entreprises ont utilité à recourir au web scraping, à la lumière d'une étude de cas de l'un de nos clients.
Pourquoi faire du web scraping?
1. L'activité commerciale
Le recours au web scraping permet à une entreprise de surveiller son activité commerciale, ainsi que celle du marché. Les informations recueillies constituent alors un indicateur de performance pertinent, dont les résultats servent à confirmer ou à modifier le plan d'action opérationnel.
Différents points peuvent être ainsi surveillés, notamment :
- contrôler les prix de ces produits pratiqués par des revendeurs ;
- surveiller leur évolution en temps réel, pour connaître l'offre de marché en permanence ;
- opérer une veille concurrentielle, afin de comparer les tarifs pratiqués sur le même segment ;
- surveiller les tendances du marché ;
- prendre des décisions marketing ou juridiques qui s'imposent.
2. Réalisation technique
La structure de web scraping est relativement simple. L'architecture se compose de crawler et de scraper :
- Le crawler est une intelligence artificielle qui explore le web à la recherche d’informations nécessaire comme si c’était un internaute lambda. La différence notable est que ce robot d'indexation le fait bien plus rapidement et sur un nombre très important de sites internet.
- Le scraper est un outil spécifique servant à extraire l’information d'une page Web. La structure et la technicité des scrapers peuvent différer sensiblement selon le projet envisagé.
3. Légal
Sur un plan juridique le sujet est complexe. Copier du contenu non libre d'un site internet pourrait être considéré comme un viol de la propriété intellectuelle de ce site. En réalité, le processus de scraping en tant que tel, n'est pas répréhensible. S'il l'était, cela reviendrait à condamner notre internaute lambda qui glane des informations sur un moteur de recherche. Si celui-ci les utilise pour son propre usage, il fait purement et simplement du scraping et il en a le droit. Le problème se poserait seulement dans l'hypothèse où il venait à plagier ces informations sans les remanier, puis à les publier. Ce n'est donc pas l'action de scraping qui pose problème, mais bien le traitement qui est effectué avec les données recueillies.
Notre étude de cas
Notre client est une marque qui vend des produits par l'intermédiaire de plus d'une centaine de revendeurs sur le net (retailers). Il souhaitait vérifier que les clauses du contrat qui le lie à ses sous-traitants étaient correctement respectés par ces derniers.
Pour cela, il avait besoin de connaître l'état des stocks et le prix de vente chez chacun de ses partenaires commerciaux d’une manière régulière.
Réalisation technique du projet de web scraping
Nous avons créé un cadre pour cette mission de web scraping, afin que les métadonnées recueillies puissent, après analyse, apporter des réponses appropriées aux demandes d'information de notre client. L'infrastructure ainsi conçue est hébergée sur le cloud. Les tâches étaient planifiées par Cloud Scheduler, lequel a déclenché le timer au moment opportun.
Les éléments techniques utilisés ont été les suivants : sur la base d'une architecture programmée en Python, l'outil Google Scheduler a déclenché le serveur de gestion des workflows, Airflow. Ce dernier a effectué le scraping de 9.000 pages Web, glanées sur 150 sites internet, en simulant le comportement d’un utilisateur intéressé par les produits de la marque de luxe. Puis, les résultats qui ont été accrochés dans les filets de la « spider » de la plateforme Apache Airflow, ont été envoyés à destination du logiciel d'analyse Google BigQuery. Ce dernier a alors extrait des éléments statistiques chiffrés.
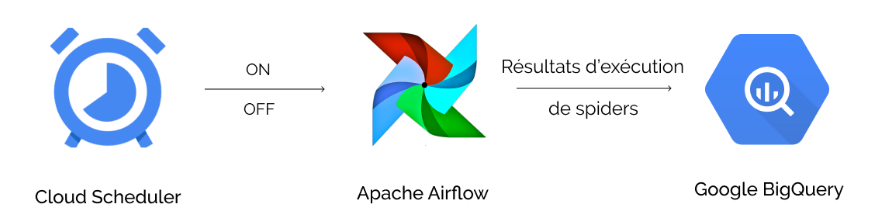 Le schéma de notre architecture sur Google Cloud Platform
Le schéma de notre architecture sur Google Cloud Platform
Grâce à ce travail de web scraping, notre client a obtenu très rapidement des indicateurs relatifs aux informations qui lui étaient essentielles. Il a pu ainsi, sur cette base, prendre des décisions stratégiques sur le plan commercial et optimiser sa production. Le web scraping se révèle donc être un outil particulièrement important qui fournit des informations commerciales précieuses, permettant d'économiser du temps et d'accroître la productivité.
Enfin, quelques chiffres pour conclure
- 150 sites, 9 mille pages dynamiques parcouru par notre spider toutes les semaines ;
- les domaines contenant ces pages Web étaient situés dans plusieurs pays : États-Unis, Australie, Grande-Bretagne, Espagne, Italie, France, Allemagne, Russie, Chine et Corée du Sud ;
- une adresse IP spécifique à chacune des pages analysées a été utilisée, afin de créer un environnement comparable en tous points au comportement d'un utilisateur classique ;
- la gestion optimale des charges du serveur, consistant à activer et à désactiver automatiquement le système selon des plages horaires définies, a permis de diviser les coûts opérationnels par 4.

